1. What is MapReduce?
대용량 데이터를 처리하기 위한 분산 프로그래밍 모델
각 데이터를 각각의 종류 별로 Mapping하고 Filtering과 Sorting을 거쳐 데이터 들을 aggregate하는 분산처리 기술
2. Map Reduce 기본 과정
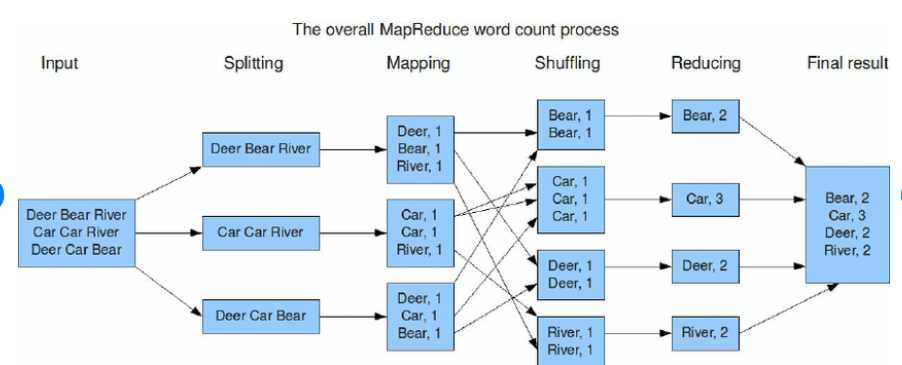
1. Splitting and Mapping
데이터들을 split 후 Mapper node에 전달 -> 각 노드에서 Map 함수 실행, (ex: Deer : 1, Bear: 1) 과 같은 Intermediate key value 생성
즉, 흩어져 잇는 데이터를 Key, Value의 형태로 연관성 있는 데이터 분류로 묶는 작업
2. Shuffling(Intermediate key value 값을 Reducer 노드 입력 전달 이전 과정)
=> 동일한 key 값을 지닌 Intermediate key value pairs를 동일한 Reducer에 전달하기 위해 필요한 과정
- Partitioning : 각각의 key 값을 기준으로 어느 reducer에서 처리될지 파티션 결정
- Sorting : 같은 파티션 내 값들을 키 값 기준으로 sorting
- Combining : 파티션 내 값들에 대해 미리 reduce 작업을 진행하여 데이터 양을 줄임
3. Reducing
reduce 결과로 생성된 결과를 별도 취합 x, hdfs에 저장
Map화한 작업 중 중복 데이터를 제거하고 원하는 데이터를 추출하는 작업
3. Map Reduce in reallife
1. Distributed Grep
- Map : 주어진 텍스트 chunk에서 정규표현식 패턴 매칭 수행, 패턴:1 생성
- Reduce : intermediate result를 그대로 복사하여 저장
2. Count URL Access Frequency
- Map : 주어진 웹 페이지 요청 로그 데이터 청크에서 URL: 1 생성
- Reduce : 찾아낸 값들을 모두 합쳐서 URL : total count 생성
3. Reverse Web-Link Graph
- Map : 웹 페이지 html chunk에서 특정 URL을 찾아 Target : Source 생성
- Reduce : 찾아낸 Key value 찾아서 Target: list(source) 형태의 데이터 생성
4. My Review
MapReduce에 대한 것은 처음에는 되게 생소한 기술이였지만 학교 과제를 통해 많이 접해 점점 이 개념이 익숙해지게 되었다. MapReduce가 아무래도 hdfs를 사용하여 작업을 진행하기 때문에 속도가 상당히 느려 최근에는 spark를 이용해 작업을 많이 진행한다고 한다. 하지만 여전히 대용량 데이터를 처리하는 곳에서도 쓰이는 기술이다.
'Hadoop' 카테고리의 다른 글
| [Hadoop] What is Pig? (4) | 2024.09.30 |
|---|---|
| YARN vs Multi Node Kubernetes (3) | 2024.06.27 |
| [Hadoop] Hadoop vs Spark (3) | 2024.06.08 |
| [Hadoop] What is HDFS ? (0) | 2024.06.01 |
| [Hadoop] How to install Hadoop in GCP? (0) | 2023.07.17 |